| ⇦ prev | ⇱ home | next ⇨ |
5.7. Alternatives to LockingThe Linux kernel provides a number of powerful locking primitives that can be used to keep the kernel from tripping over its own feet. But, as we have seen, the design and implementation of a locking scheme is not without its pitfalls. Often there is no alternative to semaphores and spinlocks; they may be the only way to get the job done properly. There are situations, however, where atomic access can be set up without the need for full locking. This section looks at other ways of doing things. 5.7.1. Lock-Free AlgorithmsSometimes, you can recast your algorithms to avoid the need for locking altogether. A number of reader/writer situations—if there is only one writer—can often work in this manner. If the writer takes care that the view of the data structure, as seen by the reader, is always consistent, it may be possible to create a lock-free data structure. A data structure that can often be useful for lockless producer/consumer tasks is the circular buffer . This algorithm involves a producer placing data into one end of an array, while the consumer removes data from the other. When the end of the array is reached, the producer wraps back around to the beginning. So a circular buffer requires an array and two index values to track where the next new value goes and which value should be removed from the buffer next. When carefully implemented, a circular buffer requires no locking in the absence of multiple producers or consumers. The producer is the only thread that is allowed to modify the write index and the array location it points to. As long as the writer stores a new value into the buffer before updating the write index, the reader will always see a consistent view. The reader, in turn, is the only thread that can access the read index and the value it points to. With a bit of care to ensure that the two pointers do not overrun each other, the producer and the consumer can access the buffer concurrently with no race conditions. Figure 5-1 shows circular buffer in several states of fill. This buffer has been defined such that an empty condition is indicated by the read and write pointers being equal, while a full condition happens whenever the write pointer is immediately behind the read pointer (being careful to account for a wrap!). When carefully programmed, this buffer can be used without locks. Figure 5-1. A circular buffer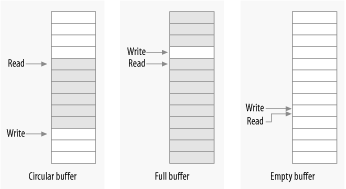 Circular buffers show up reasonably often in device drivers. Networking adaptors, in particular, often use circular buffers to exchange data (packets) with the processor. Note that, as of 2.6.10, there is a generic circular buffer implementation available in the kernel; see <linux/kfifo.h> for information on how to use it. 5.7.2. Atomic VariablesSometimes, a shared resource is a simple integer value. Suppose your driver maintains a shared variable n_op that tells how many device operations are currently outstanding. Normally, even a simple operation such as: n_op++; would require locking. Some processors might perform that sort of increment in an atomic manner, but you can't count on it. But a full locking regime seems like overhead for a simple integer value. For cases like this, the kernel provides an atomic integer type called atomic_t, defined in <asm/atomic.h>. An atomic_t holds an int value on all supported architectures. Because of the way this type works on some processors, however, the full integer range may not be available; thus, you should not count on an atomic_t holding more than 24 bits. The following operations are defined for the type and are guaranteed to be atomic with respect to all processors of an SMP computer. The operations are very fast, because they compile to a single machine instruction whenever possible.
As stated earlier, atomic_t data items must be accessed only through these functions. If you pass an atomic item to a function that expects an integer argument, you'll get a compiler error. You should also bear in mind that atomic_t values work only when the quantity in question is truly atomic. Operations requiring multiple atomic_t variables still require some other sort of locking. Consider the following code: atomic_sub(amount, &first_atomic); atomic_add(amount, &second_atomic); There is a period of time where the amount has been subtracted from the first atomic value but not yet added to the second. If that state of affairs could create trouble for code that might run between the two operations, some form of locking must be employed. 5.7.3. Bit OperationsThe atomic_t type is good for performing integer arithmetic. It doesn't work as well, however, when you need to manipulate individual bits in an atomic manner. For that purpose, instead, the kernel offers a set of functions that modify or test single bits atomically. Because the whole operation happens in a single step, no interrupt (or other processor) can interfere. Atomic bit operations are very fast, since they perform the operation using a single machine instruction without disabling interrupts whenever the underlying platform can do that. The functions are architecture dependent and are declared in <asm/bitops.h>. They are guaranteed to be atomic even on SMP computers and are useful to keep coherence across processors. Unfortunately, data typing in these functions is architecture dependent as well. The nr argument (describing which bit to manipulate) is usually defined as int but is unsigned long for a few architectures. The address to be modified is usually a pointer to unsigned long, but a few architectures use void * instead. The available bit operations are:
When these functions are used to access and modify a shared flag, you don't have to do anything except call them; they perform their operations in an atomic manner. Using bit operations to manage a lock variable that controls access to a shared variable, on the other hand, is a little more complicated and deserves an example. Most modern code does not use bit operations in this way, but code like the following still exists in the kernel. A code segment that needs to access a shared data item tries to atomically acquire a lock using either test_and_set_bit or test_and_clear_bit. The usual implementation is shown here; it assumes that the lock lives at bit nr of address addr. It also assumes that the bit is 0 when the lock is free or nonzero when the lock is busy. /* try to set lock */
while (test_and_set_bit(nr, addr) != 0)
wait_for_a_while( );
/* do your work */
/* release lock, and check... */
if (test_and_clear_bit(nr, addr) = = 0)
something_went_wrong( ); /* already released: error */If you read through the kernel source, you find code that works like this example. It is, however, far better to use spinlocks in new code; spinlocks are well debugged, they handle issues like interrupts and kernel preemption, and others reading your code do not have to work to understand what you are doing. 5.7.4. seqlocksThe 2.6 kernel contains a couple of new mechanisms that are intended to provide fast, lockless access to a shared resource. Seqlocks work in situations where the resource to be protected is small, simple, and frequently accessed, and where write access is rare but must be fast. Essentially, they work by allowing readers free access to the resource but requiring those readers to check for collisions with writers and, when such a collision happens, retry their access. Seqlocks generally cannot be used to protect data structures involving pointers, because the reader may be following a pointer that is invalid while the writer is changing the data structure. Seqlocks are defined in <linux/seqlock.h>. There are the two usual methods for initializing a seqlock (which has type seqlock_t): seqlock_t lock1 = SEQLOCK_UNLOCKED; seqlock_t lock2; seqlock_init(&lock2); Read access works by obtaining an (unsigned) integer sequence value on entry into the critical section. On exit, that sequence value is compared with the current value; if there is a mismatch, the read access must be retried. As a result, reader code has a form like the following: unsigned int seq;
do {
seq = read_seqbegin(&the_lock);
/* Do what you need to do */
} while read_seqretry(&the_lock, seq);This sort of lock is usually used to protect some sort of simple computation that requires multiple, consistent values. If the test at the end of the computation shows that a concurrent write occurred, the results can be simply discarded and recomputed. If your seqlock might be accessed from an interrupt handler, you should use the IRQ-safe versions instead: unsigned int read_seqbegin_irqsave(seqlock_t *lock,
unsigned long flags);
int read_seqretry_irqrestore(seqlock_t *lock, unsigned int seq,
unsigned long flags);Writers must obtain an exclusive lock to enter the critical section protected by a seqlock. To do so, call: void write_seqlock(seqlock_t *lock); The write lock is implemented with a spinlock, so all the usual constraints apply. Make a call to: void write_sequnlock(seqlock_t *lock); to release the lock. Since spinlocks are used to control write access, all of the usual variants are available: void write_seqlock_irqsave(seqlock_t *lock, unsigned long flags); void write_seqlock_irq(seqlock_t *lock); void write_seqlock_bh(seqlock_t *lock); void write_sequnlock_irqrestore(seqlock_t *lock, unsigned long flags); void write_sequnlock_irq(seqlock_t *lock); void write_sequnlock_bh(seqlock_t *lock); There is also a write_tryseqlock that returns nonzero if it was able to obtain the lock. 5.7.5. Read-Copy-UpdateRead-copy-update (RCU) is an advanced mutual exclusion scheme that can yield high performance in the right conditions. Its use in drivers is rare but not unknown, so it is worth a quick overview here. Those who are interested in the full details of the RCU algorithm can find them in the white paper published by its creator (http://www.rdrop.com/users/paulmck/rclock/intro/rclock_intro.html). RCU places a number of constraints on the sort of data structure that it can protect. It is optimized for situations where reads are common and writes are rare. The resources being protected should be accessed via pointers, and all references to those resources must be held only by atomic code. When the data structure needs to be changed, the writing thread makes a copy, changes the copy, then aims the relevant pointer at the new version—thus, the name of the algorithm. When the kernel is sure that no references to the old version remain, it can be freed. As an example of real-world use of RCU, consider the network routing tables. Every outgoing packet requires a check of the routing tables to determine which interface should be used. The check is fast, and, once the kernel has found the target interface, it no longer needs the routing table entry. RCU allows route lookups to be performed without locking, with significant performance benefits. The Starmode radio IP driver in the kernel also uses RCU to keep track of its list of devices. Code using RCU should include <linux/rcupdate.h>. On the read side, code using an RCU-protected data structure should bracket its references with calls to rcu_read_lock and rcu_read_unlock. As a result, RCU code tends to look like: struct my_stuff *stuff; rcu_read_lock( ); stuff = find_the_stuff(args...); do_something_with(stuff); rcu_read_unlock( ); The rcu_read_lock call is fast; it disables kernel preemption but does not wait for anything. The code that executes while the read "lock" is held must be atomic. No reference to the protected resource may be used after the call to rcu_read_unlock. Code that needs to change the protected structure has to carry out a few steps. The first part is easy; it allocates a new structure, copies data from the old one if need be, then replaces the pointer that is seen by the read code. At this point, for the purposes of the read side, the change is complete; any code entering the critical section sees the new version of the data. All that remains is to free the old version. The problem, of course, is that code running on other processors may still have a reference to the older data, so it cannot be freed immediately. Instead, the write code must wait until it knows that no such reference can exist. Since all code holding references to this data structure must (by the rules) be atomic, we know that once every processor on the system has been scheduled at least once, all references must be gone. So that is what RCU does; it sets aside a callback that waits until all processors have scheduled; that callback is then run to perform the cleanup work. Code that changes an RCU-protected data structure must get its cleanup callback by allocating a struct rcu_head, although it doesn't need to initialize that structure in any way. Often, that structure is simply embedded within the larger resource that is protected by RCU. After the change to that resource is complete, a call should be made to: void call_rcu(struct rcu_head *head, void (*func)(void *arg), void *arg); The given func is called when it is safe to free the resource; it is passed to the same arg that was passed to call_rcu. Usually, the only thing func needs to do is to call kfree. The full RCU interface is more complex than we have seen here; it includes, for example, utility functions for working with protected linked lists. See the relevant header files for the full story. |
| ⇦ prev | ⇱ home | next ⇨ |